Empower Business Owners to Validate AI
GGX provides the safe environment your Subject Matter Experts (SMEs) need to stress-test scenarios, flag behavioural gaps, and verify fixes before your AI reaches a single customer.
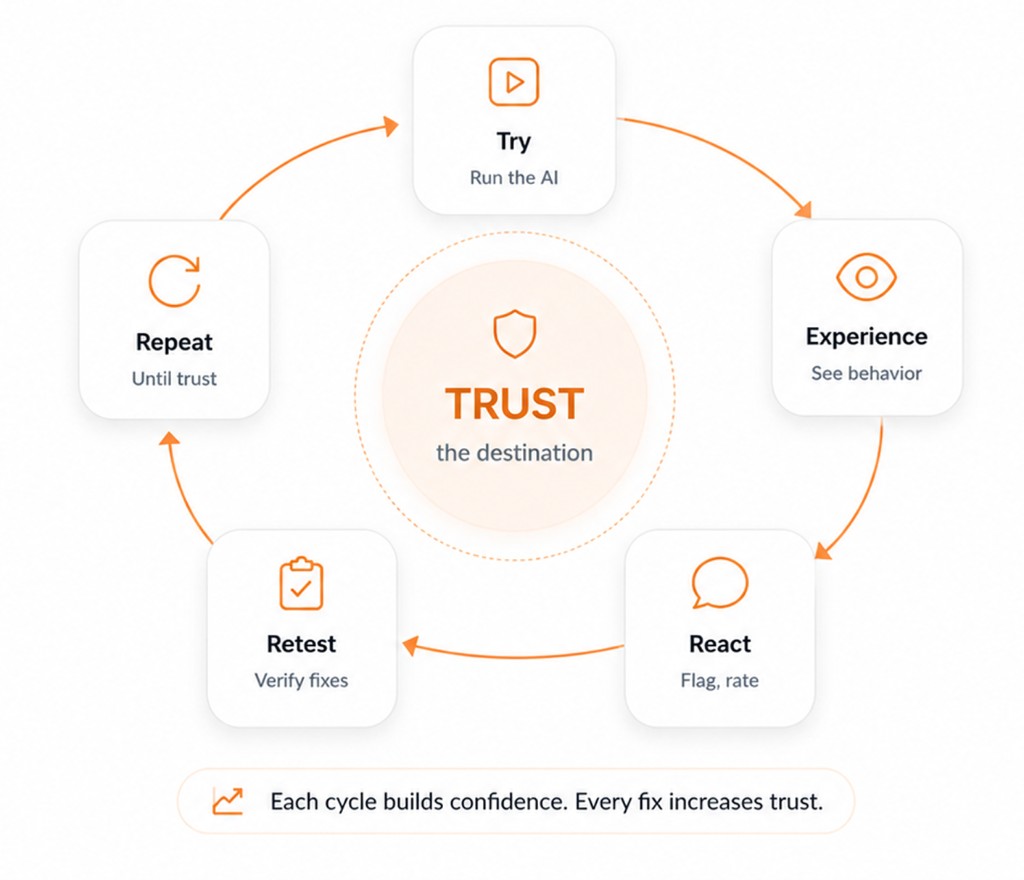
Interactive playground
Business users run realistic scenarios against the AI application before launch - no developer required.
Feedback portal
One-click flagging, ratings, and structured findings on every interaction.
Findings database
Every issue tracked from raised to resolved, no scattered feedback lost.
Progress tracking
Version-over-version proof that issues are being fixed.
Every business reaction becomes ground truth
Every flag, rating, and annotation from a business user becomes reusable ground truth. GGX turns SME feedback into structured data that supports objective measurement, faster iteration, monitoring, and future evaluation sets. Capture it once. Reuse it throughout the AI lifecycle.